前言
RockDB将一个SST文件称为一个表,针对业务场景不同,RocksDB提供了多种类型的表,其中BlockBasedTable是默认的并且最常用的表类型。因为BlockBasedTable涉及到RocksDB与磁盘的交互,其读写过程几乎处于RocksDB读写path最底层的位置,因此该类还是非常重要的。在RocksDB的codebase中,与BlockBasedTable相关的核心类有下面几个:
- BlockBasedTable, 该类封装了用于读取磁盘BlockBasedTable类型的SST表的逻辑。
- BlockBasedTableBuilder, 该类用于在磁盘上构建一个BlockBasedTable类型的SST表。
- BlockBasedTableFactory, RocksDB通过工厂方法模式来创建TableReader/TableBuilder, BlockBasedTableFactory是BlockBasedTable工厂方法的实现,用于创建BlockBasedTable/BlockBasedTableBuilder。
BlockBasedTableBuilder与BlockBasedTableFactory逻辑比较简单,本文主要分析BlockBasedTable的实现。
BlockBasedTable
一个BlockBasedTable对象代表一个SST对象,RocksDB管理的磁盘上的数据是非覆写的,BlockBasedTable向上层提供了读取磁盘数据的接口。
核心数据域
BlockBasedTable的核心数据是一个BlockBasedTable::Rep结构体。该结构体主要field如下:
/*
* RandomAccessFileReader其实就是对磁盘上文件的封装,用于读取文件的内容
*/
unique_ptr<RandomAccessFileReader> file;
/*
* 一个BlockBasedTable的数据在blockcache中,有相同的key前缀
* 这个前缀在linux系统下其实就是table文件的fd
*/
char cache_key_prefix[kMaxCacheKeyPrefixSize];
/*
* index_reader和filter分别用于读取一个Table的index信息和filter信息
* 如果blockcache未开启,那么由BlockBasedTableReader持有index_reader和filter
*/
unique_ptr<IndexReader> index_reader;
unique_ptr<FilterBlockReader> filter;
/*
* filter block在SST文件中的位置
* TODO: 为什么filter block需要单独拎出来?index block呢
*/
BlockHandle filter_handle;
/*
* 用于记录表的一些属性信息
*/
std::shared_ptr<const TableProperties> table_properties;
/*
* 当pin_l0_filter_and_index_blocks_in_cache开启时,Table对象记录filter和index在
* block中的handle以达到pin的效果
*/
CachableEntry<FilterBlockReader> filter_entry;
CachableEntry<IndexReader> index_entry;
BlockBasedTable的核心数据有一点需要注意:当blockcache未开启,或者禁止了cache_index_and_filter_blocks,此时filter block和index block的内存由BlockBasedTable自身通过index_reader和filter两个成员变量持有。如果blockcache开启,那么此时filter block和index block通过blockcache管理,index_reader和filter两个成员不再有用。最后,如果希望将将L0层的filter和block订在blockcache中,那么使用两个成员变量filter_entry和index_entry将Cache的Handle记录下来,避免blockcache的LRU语义将其释放掉。
核心方法
BlockBasedTable::Open
BlockBasedTable::Open的一个调用栈如下。
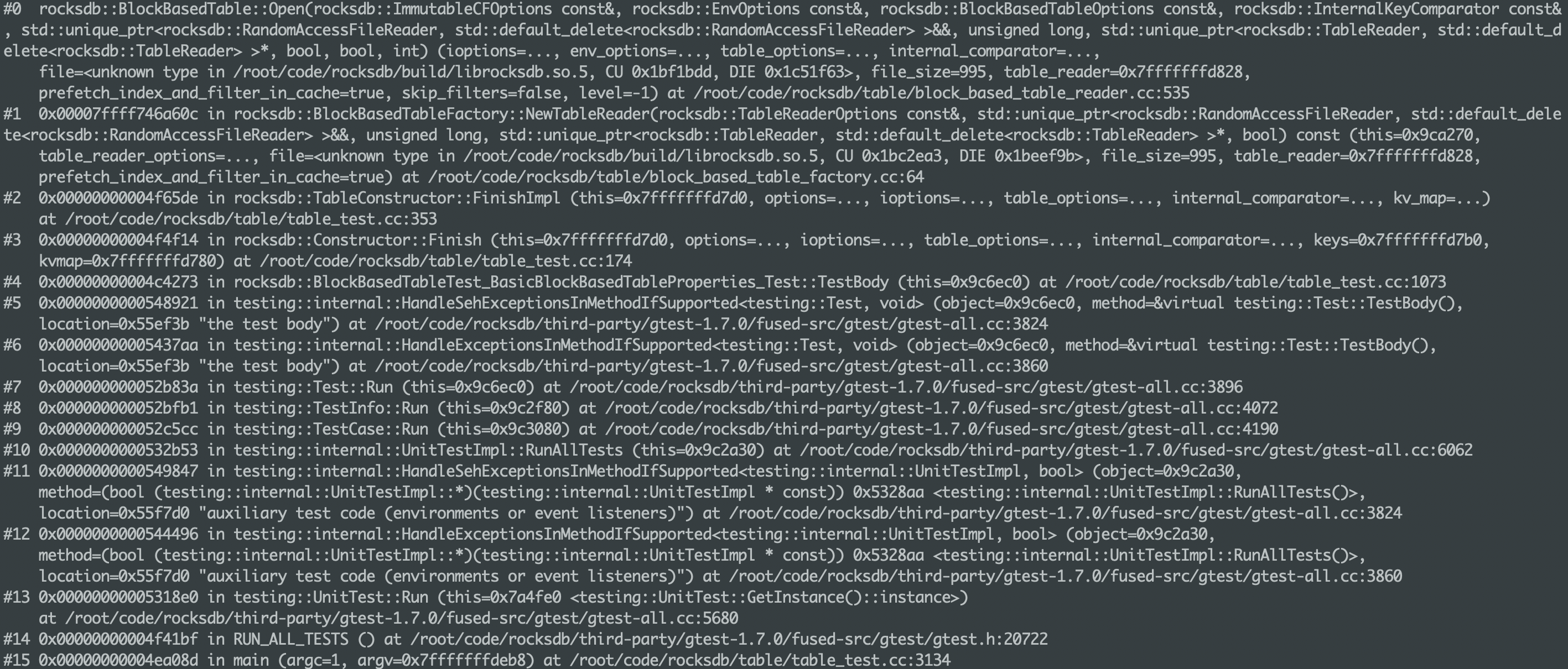 BlockBasedTable::Open主要用于初始化BlockBasedTable::rep, 并预取table的index block和filter block,其函数签名如下:
BlockBasedTable::Open主要用于初始化BlockBasedTable::rep, 并预取table的index block和filter block,其函数签名如下:
static Status Open(const ImmutableCFOptions& ioptions,
const EnvOptions& env_options,
const BlockBasedTableOptions& table_options,
const InternalKeyComparator& internal_key_comparator,
unique_ptr<RandomAccessFileReader>&& file,
uint64_t file_size, unique_ptr<TableReader>* table_reader,
bool prefetch_index_and_filter_in_cache = true,
bool skip_filters = false, int level = -1);
参数列表中的table_reader为传出参数,成功Open则赋值table_reader,该函数的主要执行流程如下:
- 读SST文件的Footer,用于判断打开的文件是否是合法的SST文件
- 读index block
- 读filter block
- 读表properties
- 如果开启了cache_index_and_filter_blocks,并且设置了预取index和filter 又或者该table属于L0层,则将index block和filter block预取到block cache中。
- 如果未开启cache_index_and_filter_blocks,不会通过blockcache管理index/filter block,而是通过BlockBasedTable的成员变量,此时会预取这些block到成员变量中。
BlockBasedTable::Close
当需要读取的数据不在blockcache中,会调用Open方法打开一个BlockBasedTable用于数据的读取。根据上一节的内容,我们看到,在Open一张表时,会缓冲index block和filter block,那当一张表关闭时当然会释放掉这些数据。Close函数的代码如下:
void BlockBasedTable::Close() {
rep_->filter_entry.Release(rep_->table_options.block_cache.get());
rep_->index_entry.Release(rep_->table_options.block_cache.get());
rep_->range_del_entry.Release(rep_->table_options.block_cache.get());
// cleanup index and filter blocks to avoid accessing dangling pointer
if (!rep_->table_options.no_block_cache) {
char cache_key[kMaxCacheKeyPrefixSize + kMaxVarint64Length];
// Get the filter block key
auto key = GetCacheKey(rep_->cache_key_prefix, rep_->cache_key_prefix_size,
rep_->filter_handle, cache_key);
rep_->table_options.block_cache.get()->Erase(key);
// Get the index block key
key = GetCacheKeyFromOffset(rep_->cache_key_prefix,
rep_->cache_key_prefix_size,
rep_->dummy_index_reader_offset, cache_key);
rep_->table_options.block_cache.get()->Erase(key);
}
}
Close函数对于pin到blockcache中的filter和index,首先做Release。接着为了避免table关闭后,仍有线程通过filter和index读取data block,Close将filter和block从blockcache中彻底删除。这里有一个细节,table关闭后,blockcache缓冲的该table的data block并没有做Erase。主要的原因是rocksdb需要通过index block访问data数据,但是data block读就读了,即使table关闭也没有影响。
BlockBasedTable::Get
Get函数用于在table中根据caller指定的key检索对应的数据。其整个流程也比较简单:
- 获取bloom filter,如果filter block不在blockcache中,则从文件中读取
- 根据获取的filter,判断key是否在当前table中,不在就直接返回
- 如果bloom filter判断数据可能在当前table中,那么构建IndexIterator。构建IndexIterator的过程需要读Index block,同样如果Index block不在blockcache中,那么需要读盘
- 通过IndexIterator二分查找caller指定的key,然后定位到对应的data block
- 如果data block不在blockcache中,那么读盘,然后将其Insert到blockcache中
- 在读取到data block中检索caller指定的key
BlockBasedTable::Get会多次与blockcache交互,交互的过程主要通过BlockBasedTable::MaybeLoadDataBlockToCache完成。MaybeLoadDataBlockToCache的函数签名如下。
Status BlockBasedTable::MaybeLoadDataBlockToCache(
Rep* rep, const ReadOptions& ro, const BlockHandle& handle,
Slice compression_dict, CachableEntry<Block>* block_entry, bool is_index) {
const bool no_io = (ro.read_tier == kBlockCacheTier)
在该函数的参数列表中,handle记录了要读取的block在SST文件中的偏移,block_entry: 出参,记录了检索到的value。MaybeLoadDataBlockToCache从blockcache读数据,如果读不到则从SST文件中读取,并将其加入到blockcache中。